SA3
TSA3.2.3: Operate certification and testing test beds

SA3 |
Torque/Maui certification Plan and ResultsFebruary 14, 2007 |
Table of Contents:
|
1 - Conclusions for the impatient reader |
The Torque-Maui batch system should be considered as one of the most robust components in the software stack used by a grid site. All of the test cases described in the following report have been executed numerous times. There were repetitions of these tests that did not conclude, yet Torque-Maui was rarely the reason for that. It is because Torque-Maui comes last in the chain of steps required for a job to be completed and most of the times failures of other software components did not allow the tests to reach this point. On the other hand functionality and stress tests designed to submit jobs directly to the Local Resource Management System (LRMS), showed that Torque-Maui handles load very well and behaves as expected. In fact given an average grid site configuration and normal usage patterns, it is quite difficult to stress a server node dedicated to the Torque-Maui system, before other nodes of gLite Middleware (e.g. WMS, gliTeCE) have already reached their limits.
Regarding Maui, apart from some additional configuration steps needed to be performed during the installation, there is only a memory management issue worth mentioning. Maui's process size is proportional to its maximum queue length. As the maximum length of its queues increases its process size also increases and never frees the allocated memory even after hours of idle time and empty queues. While this might be considered normal behavior, in accordance with its internal design and internal structure management, it requires careful planning of the memory resources allocated to the node that will host Torque and Maui servers.
2 - Introduction |
Information for the latest version:
| Document Name: | Torque/Maui certification
Test Plan and Results |
| Version: | 1.0 |
| Publication Date: | 2007-02-13 |
| Author(s): | Nikos Voutsinas, Dimitrios Apostolou, Kostantinos Koukopoulos |
| Contact: | For any questions or comments about this document please contact contact@gridctb.uoa.gr |
| Status: | In progress |
Revision history
| Version | Date | Partner/Author(s) | comments |
| 1.2 | 2007-02-14 | UOA/Nikos Voutsinas UOA/Dimitrios Apostolou UOA/Konstantinos Koukopoulos | First Release Torque 2.1.6, Maui 3.2.6p17 |
Torque-Maui is the proposed LRMS from gLite middleware. In the framework of SA3 activity, GRNET/UOA is the responsible partner for the certification of new Torque-Maui releases. This document provides a description of the certification method followed. In particular, it addresses the specification of the:
3.- Certification Approach |
The test cases are organized in two levels. The first level covers the Torque-Maui as part of the full stack of gLite middleware. In this case, test cases are based on gLite tools related with grid job submission and resource monitoring. The second level concentrates on verifying the Torque-Maui as a stand alone batch system independently of other middleware components. Different types of test cases covered the certification needs in each level for the full range of functionality, stress and performance tests.
Also, the certification covers both the installation and configuration of Torque-Maui, as well as the run time behaviour.
The installation and configuration scenarios include test cases to verify that:
In order to validate the entire system against its operational requirements, the related scenarios include test cases to verify that
The test framework consists of several processes and utilities to facilitate testing automation and results analysis. The following are considered as the main building blocks of this framework:
:pserver:anoncvs@email.uoa.gr/egee (Web access)Various limitations such as the number of available hardware resources and test environment configuration need to be considered during the evaluation of the test results. Due to these limitations, there were test cases that could not be executed.
The most important limitations on the current version were the following:
All of the above limit the test coverage on concurrency issues and the simulation of specific real world usage patterns
.A test suite (bash shell scripts) has been developed in order to support a series of test cases, especially those that covered Stress, Performance and Resource tests. An external node (See Test Environment) has been used to execute the test script in test cases where script operation might impact the test results.
In order to proceed with a quantitative analysis of the results, metrics were specified to facilitate system and process monitoring. A collection of bash shell scripts and cron jobs are used to gather monitoring data from the involved grid nodes on per minute basis and store them on text files that reside on an NFS filesystem. Following that, to ease the comparison and in depth analysis of the results, a batch process inserts monitoring data to a database backend. To illustrate test results and conclusions, monitoring data are provied through graphical representation when appropriate.
| Nodes | data types | |||||||
|---|---|---|---|---|---|---|---|---|
| Load Average | %cpu,size | Jobs Status | ||||||
| pbs_server | pbs_mom | maui | BLParserPBS | GIP | BDII | qstat | ||
| gliteCE/SiteBDII | X | X | X | |||||
| Worker | X | X | ||||||
| Torque/Maui | X | X | X | X | X | |||
4.- Test Environment |
5.- Performed Tests |
The following table gives an overview of the test cases and links to more detailed test case descriptions.
| Test case | Description |
|---|---|
| 5.1. | check Batch System information published through BDII |
| 5.2. | check Batch System configuration |
| 5.3. | check network ports and services |
| 5.4. | check logging |
| 5.5. | checking General Information Providers (GIPs) |
| 5.5. | job submission of few long lived, cpu intensive jobs |
| 5.7. | 200 job submissions using 1 WMS |
| 5.8. | 400 job submissions using 2 WMS |
| 5.9. | 300 job submissions using 3 WMS |
| 5.10. | job submissions directly to Torque |
| 5.11. | parallel job submissions directly to Torque |
| 5.12. | Stressing the LRMS memory management |
| 5.13. | Batch System Resilience Tests |
lcg-info-dynamic-scheduler-wrapper results provided by
rgma user (every 10mins) are ok. Instead
lcg-info-dynamic-scheduler-wrapper results provided by
edguser user (every 1 min) use static ldif beacause of the
user insufficient permissions. The problem was resolved when edguser
was added to the ADMIN line in /var/spool/maui/maui.cfg
in TORQUE_server node. Why is the BDII being updated from both the
rgma (every 10 min) and the edguser (every 1 min) users?
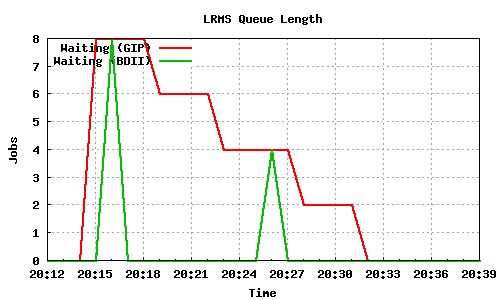
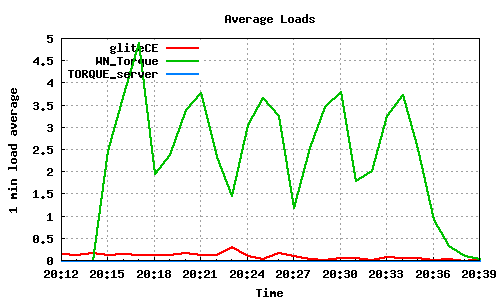
10 long lived, cpu intensive jobs
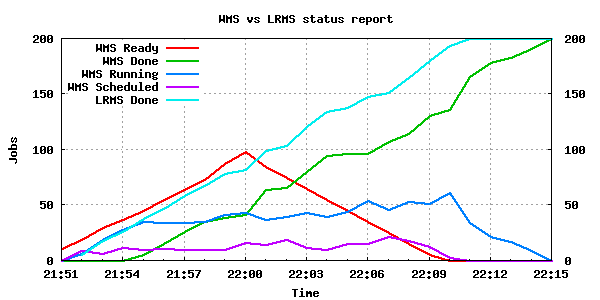
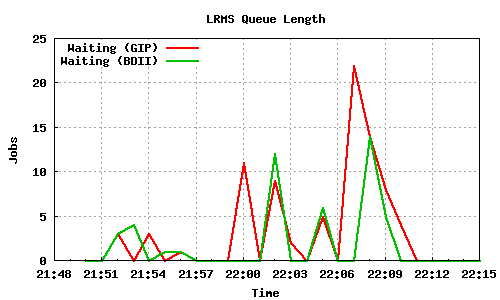
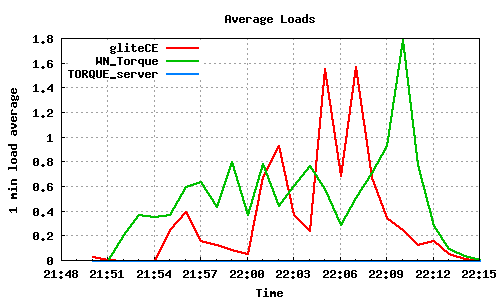
200 job submissions using 1 WMS
This test is not capable of stressing gliteCE or TORQUE_server either, as the load average is minimal on these nodes. However it seems that jobs are being submitted faster than being run (even though they are instantaneous) and LRMS's queue reaches a maximum length of 118.
The only Grid component that seems to be stressed in this test is the WMS, in particular WMS-3, even though the same number of jobs were submitted to WMS-3 and WMS-1. Perhaps this is a result of network distance between the UIs and WMS-3, or overload due to other submissions taking place, or generally because of bad scalability of the WMS subsystem. It should finally be noted that WMS-3 reported for a short period of time incorrect numbers, such as 0 jobs completed (22:53-22:54) or more jobs completed than the actual results (23:12).
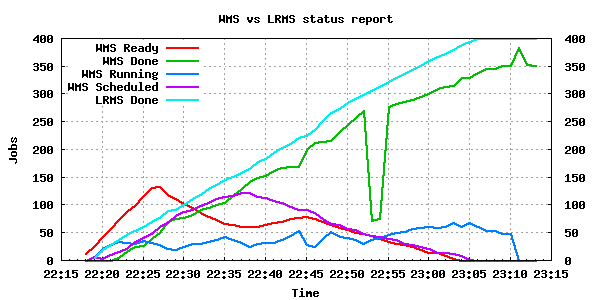
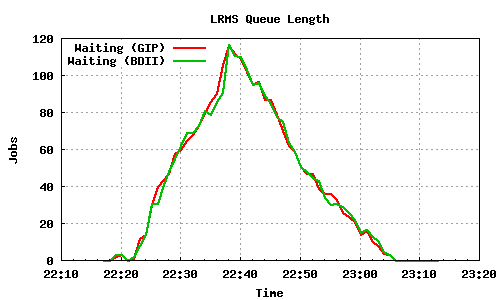
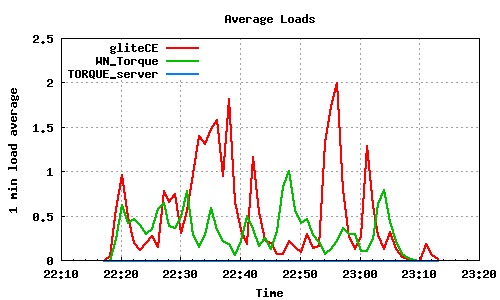
400 job submissions using 2 WMS
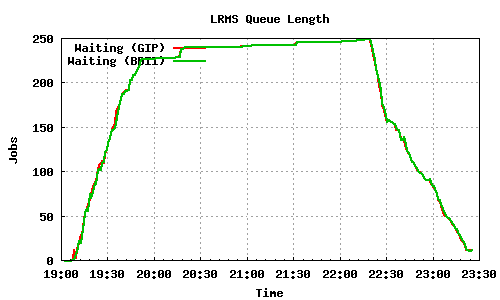
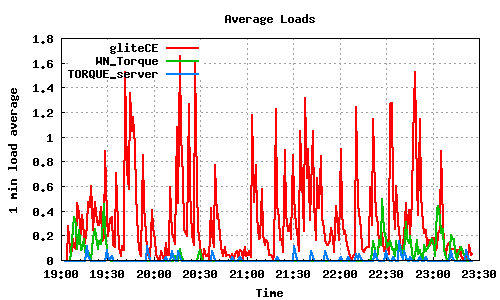
600 job submissions using 3 WMS
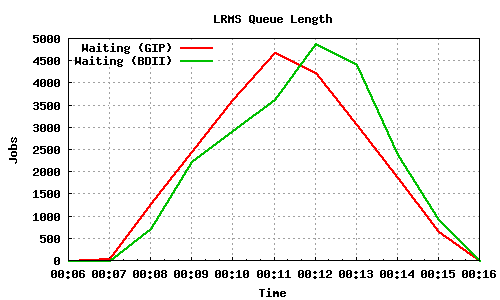
The following graph pairs depict the queue length (as reported by GIP and the BDII) and the average load on the CE, WN and LRMS, during the 1000,2000,4000 and 5000 job submissions (qsub). The TORQUE_server is stressed only on the last two cases, but handles the load gracefully and performs correctly. Further stressing could possibly be applied on that node by submitting the jobs to many Worker Nodes.
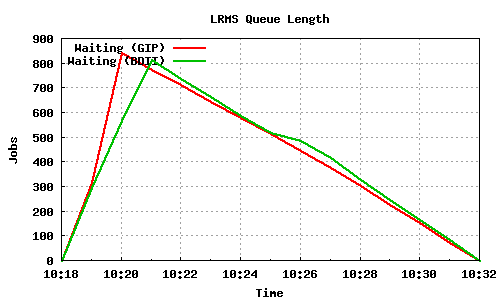
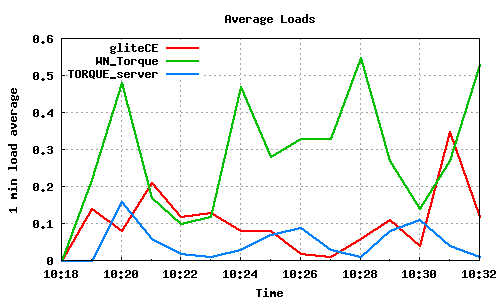
1000 jobs submitted directly to Torque
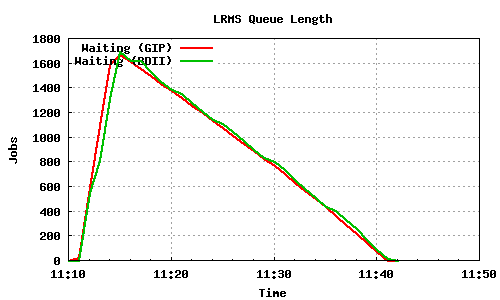
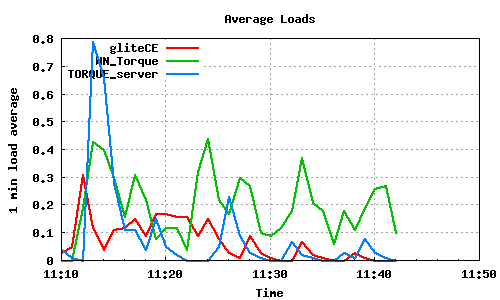
2000 jobs submitted directly to Torque
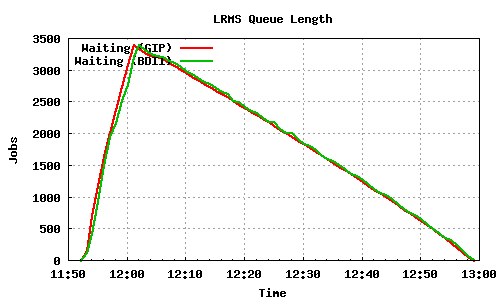

4000 jobs submitted directly to Torque
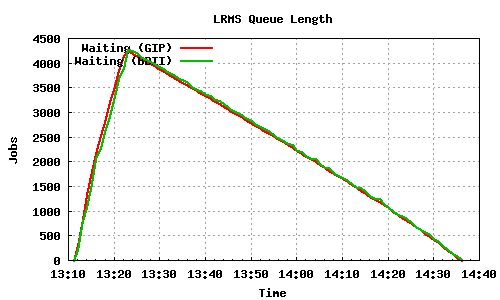
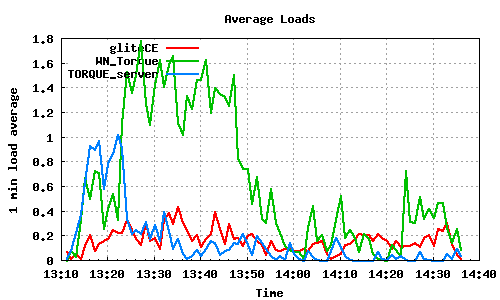
5000 jobs submitted directly to Torque
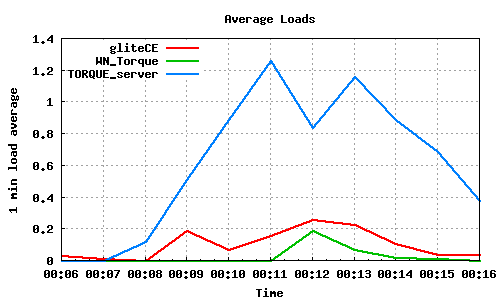
50x100 parallel job submissions directly to Torque
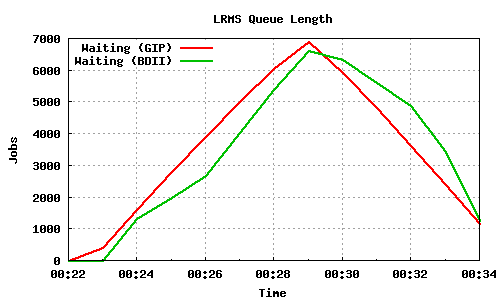
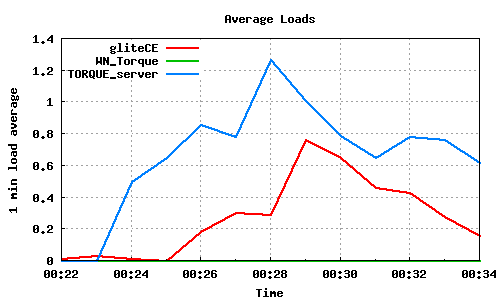
70x100 parallel job submissions directly to Torque
maui and pbs_server processes.
1000-7000 instantaneous jobs were serially submitted, or 70 threads of
100 iterations each were in parallel performing qsub and qdel, in various
combinations.
The first two graphs show the memory usage and queue length of the maui and pbs_server processes during the submission of batches of 1000, 2000, 4000, 5000 jobs followed by 5000 and 7000 parallel submissions/deletions. The maui process starts with almost 70MB memory usage, which stabilizes in a higher value after each submission batch. After the final (7000 qsub/qdel) job batch, maui stabilizes its memory usage to more than 335MB. The pbs_server memory footprint also grows with each job submission but we see that much of the memory used during the submission is freed after the end.
From this test as well as from other similar tests carried out, it is evident that maui does not free any significant part of it's allocated memory even after long periods of inactivity. This could pose a significant problem to other processes running on the same machine. In the event of a surge in job submissions maui claims memory that it doesn't ever release. It is not uncommon to see the memory usage of maui constant at over 300MB, after some uptime of the corresponding node.
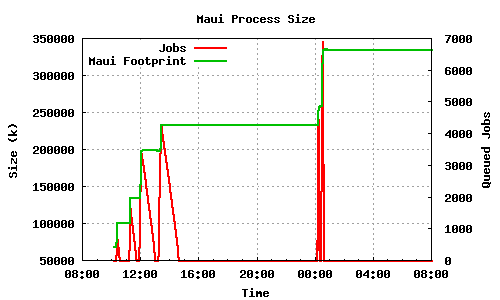
LRMS memory usage case 1
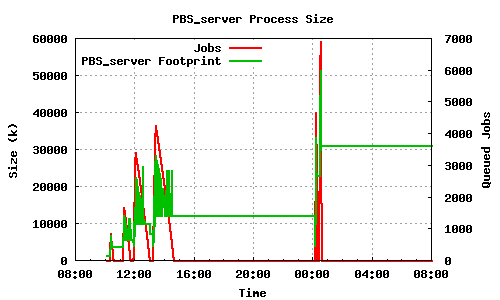
pbs_server on the other hand behaves better, as can be seen in the next two graphs. The graphs depict the memory footprint and queue length during the course of three 7000 qsub/qdel's followed by three 5000 qsub's. While maui keeps all the memory it needed during the job submission, pbs_server stabilizes at a much lower memory footprint than what it needed during the submission:
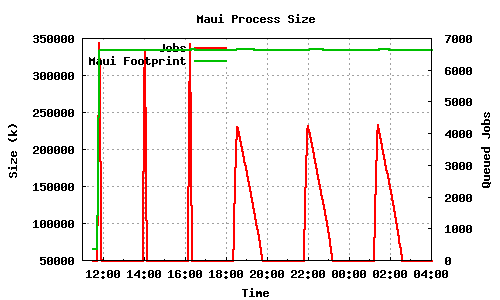
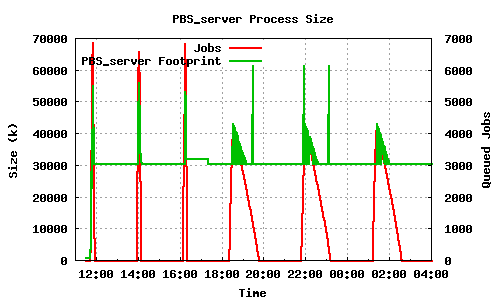
LRMS memory usage case 2
pbs_server and TORQUE_server node, and starting it again
after a while.
No matter the state of the WN, the job already running on it was never lost. The only result of bringing the WN offline or down was that no more jobs were being submitted to it until remarking it online. Moreover in the case of switching the state of the WN down the WN, after a few seconds it was automatically marked online by the LRMS which realized that it was not truly down.
Stopping the pbs_server only caused the relevant
command-line utilities to stop working, but again no jobs were lost
and queue was resumed normally a while after restarting the service.
Appendix A: Required Modifications |
/var/spool/pbs/mom_priv/config $clienthost is deprecated
and should be replaced by $pbsserver, followed by the address of
TORQUE_server node./opt/glite/yaim/functions/config_gip_scheduler_plugin the
switch -h should be added on vomaxjobs-maui
command. See bug
#16976 for further information./var/spool/maui/maui.cfg
SERVERHOST should point to the TORQUE_server node instead of
localhost.echo "/opt/glite/bin/BLParserPBS -D -p 33332 -s /var/spool/pbs" >> /etc/rc.local
/var/spool/maui/maui.cfg) edguser should be included in
ADMIN3 option along with rgma user, otherwise GIP will use static
values and BDII scheduler related values will only be accurate for the time
slots where information is provided by rgma.
Appendix B: Test Data and Logs |
$ ldapsearch -h ctb03.gridctb.uoa.gr -p 2170 -x -b mds-vo-name=EGEE-SEE-CERT,\ o=grid "(&(GlueForeignKey=GlueClusterUniqueID=ctb03.gridctb.uoa.gr)"\ "(GlueCEName=dteam))" GlueCEInfoHostName GlueCEInfoLRMSType \ GlueCEInfoLRMSVersion GlueCEInfoJobManager $ ldapsearch -h ctb08.gridctb.uoa.gr -p 2170 -x -b mds-vo-name=local,\ o=grid "(&(GlueForeignKey=GlueClusterUniqueID=ctb03.gridctb.uoa.gr)"\ "(GlueCEName=dteam))" GlueCEInfoHostName GlueCEInfoLRMSType \ GlueCEInfoLRMSVersion GlueCEInfoJobManager
GlueCEInfoHostName: ctb03.gridctb.uoa.gr GlueCEInfoLRMSType: pbs GlueCEInfoLRMSVersion: 2.1.6 GlueCEInfoJobManager: pbs
[root@ctb07 root]# qmgr -c 'print server' [root@ctb07 root]# cat /var/spool/pbs/server_priv/nodes [root@ctb07 root]# showconfig [root@ctb07 root]# cat /var/spool/maui/maui.cfg [root@ctb05 root]# cat /var/spool/pbs/mom_priv/config [root@ctb03 root]# cat /opt/lcg/etc/lcg-info-dynamic-scheduler.conf
[root@ctb07 root]# qmgr -c 'print server' ........ [*]
[root@ctb07 root]# cat /var/spool/pbs/server_priv/nodes ctb05.gridctb.uoa.gr np=2 lcgpro
[root@ctb07 root]# showconfig ........ [*]
[root@ctb07 root]# cat /var/spool/maui/maui.cfg SERVERHOST ctb07.gridctb.uoa.gr ADMIN1 root ADMIN3 edginfo rgma ADMINHOST ctb07.gridctb.uoa.gr RMCFG[base] TYPE=PBS SERVERPORT 40559 SERVERMODE NORMAL RMPOLLINTERVAL 00:00:10 LOGFILE /var/log/maui.log LOGFILEMAXSIZE 10000000 LOGLEVEL 1 DEFERTIME 00:01:00 ENABLEMULTIREQJOBS TRUE
[root@ctb05 root]# cat /var/spool/pbs/mom_priv/config $pbsserver ctb07.gridctb.uoa.gr $restricted ctb07.gridctb.uoa.gr $logevent 255 $ideal_load 1.6 $max_load 2.1
[root@ctb03 root]# cat /opt/lcg/etc/lcg-info-dynamic-scheduler.conf [Main] static_ldif_file: /opt/lcg/var/gip/ldif/lcg-info-static-ce.ldif vomap : ops:ops dteam:dteam module_search_path : ../lrms:../ett [LRMS] lrms_backend_cmd: /opt/lcg/libexec/lrmsinfo-pbs [Scheduler] vo_max_jobs_cmd: /opt/lcg/libexec/vomaxjobs-maui -h ctb07.gridctb.uoa.gr cycle_time : 0
# netstat
TORQUE_server -------------- port process service ------------------------------------------ 40559 maui 40560 maui 33332 BLParserPBS 15001 pbs_server pbs 15004 maui pbs_sched 15001(udp) pbs_server pbs 1022(udp) pbs_server
WN_torque ---------- port process service ------------------------------------------ 20001 BPRserver.1811 20002 BPRserver.1811 15002 pbs_mom pbs_mom 15003 pbs_mom pbs_resmom 15003(udp) pbs_mom pbs_resmom 1022(udp) pbs_momgliteCE
---------- No listening services
[root@ctb03 root]# cat /var/log/glite/accounting/blahp.log-`date +%Y%m%d`\ |grep '10237.' [root@ctb07 root]# cat /var/spool/pbs/server_logs/`date +%Y%m%d` \ |grep '10237.' [root@ctb07 root]# cat /var/log/maui.log |grep '10237.' [root@ctb05 root]# cat /var/spool/pbs/mom_logs/`date +%Y%m%d` \ |grep '10237.'
[root@ctb03 root]# cat /var/log/glite/accounting/blahp.log-`date +%Y%m%d`\ |grep '10237.' "timestamp=2007-02-01 18:33:58" "userDN=/C=GR/O=HellasGrid/OU=gridctb.uoa.gr/CN=Nikos Voutsinas" "userFQAN=/dteam/Role=NULL/Capability=NULL" "ceID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam" "jobID=https://ctb05.gridctb.uoa.gr:9000/nEqMFsT1z5sSiSgrNrn6zQ" "lrmsID=10237.ctb07.gridctb.uoa.gr" "localUser=18118"
[root@ctb07 root]# cat /var/spool/pbs/server_logs/`date +%Y%m%d` \ |grep '10237.' 02/01/2007 20:33:51;0100;PBS_Server;Job;10237.ctb07.gridctb.uoa.gr;enqueuing into dteam, state 1 hop 1 02/01/2007 20:33:51;0008;PBS_Server;Job;10237.ctb07.gridctb.uoa.gr;Job Queued at request of dteam001@ctb03.gridctb.uoa.gr, owner = dteam001@ctb03.gridctb.uoa.gr, job name = blahjob_py4171, queue = dteam 02/01/2007 20:35:01;0008;PBS_Server;Job;10237.ctb07.gridctb.uoa.gr;Job Run at request of root@ctb07.gridctb.uoa.gr 02/01/2007 20:35:09;0010;PBS_Server;Job;10237.ctb07.gridctb.uoa.gr;Exit_status=0 resources_used.cput=00:00:01 resources_used.mem=9812kb resources_used.vmem=37876kb resources_used.walltime=00:00:08 02/01/2007 20:35:10;0100;PBS_Server;Job;10237.ctb07.gridctb.uoa.gr;dequeuing from dteam, state COMPLETE
[root@ctb07 root]# cat /var/log/maui.log |grep '10237.' 02/01 20:33:51 INFO: job '10237' loaded: 1 dteam001 dteam 259200 Idle 0 1170354831 [NONE] [NONE] [NONE] >= 0 >= 0 [NONE] 1170354831 02/01 20:33:51 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:33:55 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:02 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:07 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:12 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:17 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:22 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:29 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:33 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:39 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:43 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:49 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:52 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:52 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:34:57 MJobPReserve(10237,DEFAULT,ResCount,ResCountRej) 02/01 20:35:01 MRMJobStart(10237,Msg,SC) 02/01 20:35:01 MPBSJobStart(10237,base,Msg,SC) 02/01 20:35:01 INFO: job '10237' successfully started 02/01 20:35:11 INFO: active PBS job 10237 has been removed from the queue. assuming successful completion
[root@ctb05 root]# cat /var/spool/pbs/mom_logs/`date +%Y%m%d` \ |grep '10237.' 02/01/2007 20:35:01;0001; pbs_mom;Job;TMomFinalizeJob3;job 10237.ctb07.gridctb.uoa.gr started, pid = 24261 02/01/2007 20:35:09;0080; pbs_mom;Job;10237.ctb07.gridctb.uoa.gr;scan_for_terminated: job 10237.ctb07.gridctb.uoa.gr task 1 terminated, sid 24261 02/01/2007 20:35:09;0008; pbs_mom;Job;10237.ctb07.gridctb.uoa.gr;job was terminated
JobType = "Normal";
ShallowRetryCount = 0;
RetryCount = 0;
Executable = "job3.sh";
Arguments = "180 1";
StdOutput = "job3.out";
StdError = "job3.err";
InputSandbox = {"JOBs/job3.sh"};
OutputSandbox = {"job3.out","job3.err"};
Requirements = other.GlueCEUniqueID=="ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam";
job3.sh
#!/bin/bash
SLEEP_TIME=${1:-0};
DO_MD5=${2:-0};
FILE_MD5=${3:-/dev/urandom};
NUM_OF_BG_JOBS=2
date
hostname
whoami
pwd
if [ "$DO_MD5" != "0" -a -r $FILE_MD5 ];then
for i in `seq 1 $NUM_OF_BG_JOBS`;do
md5sum $FILE_MD5 &
job_id=$!
jobs_array[i]=$job_id
done
fi
if [ "$SLEEP_TIME" != "0" ];then
sleep $SLEEP_TIME
fi
if [ "$DO_MD5" != "0" -a -f $FILE_MD5 ];then
for i in seq `1 $NUM_OF_BG_JOBS`;do
kill ${jobs_array[i]}
done
fi
exit 0;
$ for i in `seq 1 10`; do glite-wms-job-submit -a -o IDs/ids_uoa \ -e https://ctb05.gridctb.uoa.gr:7443/glite_wms_wmproxy_server \ JDLs/ctb03_4.gridctb.uoa.gr.blah-pbs-dteam.jdl;done [root@ctb03 root]# watch "qstat -q" [root@ctb03 root]# watch showstate [root@ctb03 root]# watch /opt/lcg/var/gip/plugin/lcg-info-dynamic-scheduler-wrapper [root@ctb03 root]# watch /opt/lcg/var/gip/plugin/ce-pbs.sh
Every 2s: qstat -q Thu Feb 1 21:49:05 2007 server: ctb07.gridctb.uoa.gr Queue Memory CPU Time Walltime Node Run Que Lm State ---------------- ------ -------- -------- ---- --- --- -- ----- dteam -- 48:00:00 72:00:00 -- 2 8 -- E R ops -- 48:00:00 72:00:00 -- 0 0 -- E R
Every 2s: showstate Thu Feb 1 21:49:09 2007
cluster state summary for Thu Feb 1 21:49:10
JobName S User Group Procs Remaining StartTime
------------------ - --------- -------- ----- ----------- -------------------
(A) 10470 R dteam001 dteam 1 2:23:57:28 Thu Feb 1 21:46:38
(B) 10471 R dteam001 dteam 1 2:23:57:28 Thu Feb 1 21:46:38
usage summary: 2 active jobs 2 active nodes
[0]
[1]
Frame 01: [B]
Key: [?]:Unknown [*]:Down w/Job [#]:Down [ ]:Idle [@] Busy w/No Job [!] Drained
/opt/lcg/var/gip/plugin/lcg-info-dynamic-scheduler-wrapper)
dn: GlueVOViewLocalID=ops,GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-ops,mds-vo-name=local,o=grid GlueVOViewLocalID: ops GlueCEAccessControlBaseRule: VO:ops GlueCEStateRunningJobs: 0 GlueCEStateWaitingJobs: 0 GlueCEStateTotalJobs: 0 GlueCEStateFreeJobSlots: 0 GlueCEStateEstimatedResponseTime: 250 GlueCEStateWorstResponseTime: 500 dn: GlueVOViewLocalID=dteam,GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam,mds-vo-name=local,o=grid GlueVOViewLocalID: dteam GlueCEAccessControlBaseRule: VO:dteam GlueCEStateRunningJobs: 2 GlueCEStateWaitingJobs: 8 GlueCEStateTotalJobs: 10 GlueCEStateFreeJobSlots: 0 GlueCEStateEstimatedResponseTime: 303 GlueCEStateWorstResponseTime: 2073600 dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-ops,mds-vo-name=local,o=grid GlueCEStateRunningJobs: 0 GlueCEStateWaitingJobs: 0 GlueCEStateTotalJobs: 0 GlueCEStateEstimatedResponseTime: 250 GlueCEStateWorstResponseTime: 500 dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam,mds-vo-name=local,o=grid GlueCEStateRunningJobs: 2 GlueCEStateWaitingJobs: 8 GlueCEStateTotalJobs: 10 GlueCEStateEstimatedResponseTime: 303 GlueCEStateWorstResponseTime: 2073600
dn: GlueVOViewLocalID=ops,GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-ops,mds-vo-name=local,o=grid GlueCEAccessControlBaseRule: VO:ops GlueCEStateRunningJobs: 0 GlueCEStateWaitingJobs: 0 GlueCEStateTotalJobs: 0 GlueCEStateFreeJobSlots: 0 GlueCEStateEstimatedResponseTime: 777777 GlueCEStateWorstResponseTime: 1555554 dn: GlueVOViewLocalID=dteam,GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam,mds-vo-name=local,o=grid GlueVOViewLocalID: dteam GlueCEAccessControlBaseRule: VO:dteam GlueCEStateRunningJobs: 2 GlueCEStateWaitingJobs: 83 GlueCEStateTotalJobs: 85 GlueCEStateFreeJobSlots: 0 GlueCEStateEstimatedResponseTime: 394 GlueCEStateWorstResponseTime: 21513600 dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-ops,mds-vo-name=local,o=grid GlueCEStateRunningJobs: 0 GlueCEStateWaitingJobs: 0 GlueCEStateTotalJobs: 0 GlueCEStateEstimatedResponseTime: 777777 GlueCEStateWorstResponseTime: 1555554 dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam,mds-vo-name=local,o=grid GlueCEStateRunningJobs: 2 GlueCEStateWaitingJobs: 83 GlueCEStateTotalJobs: 85 GlueCEStateEstimatedResponseTime: 394 GlueCEStateWorstResponseTime: 21513600
/opt/lcg/var/gip/plugin/ce-pbs.sh)
dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-ops,mds-vo-name=local,o=grid GlueCEInfoLRMSVersion: 2.1.6 GlueCEInfoTotalCPUs: 2 GlueCEStateFreeCPUs: 0 GlueCEPolicyMaxCPUTime: 2880 GlueCEPolicyMaxWallClockTime: 4320 GlueCEStateStatus: Production dn: GlueCEUniqueID=ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam,mds-vo-name=local,o=grid GlueCEInfoLRMSVersion: 2.1.6 GlueCEInfoTotalCPUs: 2 GlueCEStateFreeCPUs: 0 GlueCEPolicyMaxCPUTime: 2880 GlueCEPolicyMaxWallClockTime: 4320 GlueCEStateStatus: Production
JobType = "Normal";
ShallowRetryCount = 0;
RetryCount = 0;
Executable = "job3.sh";
Arguments = "180 1";
StdOutput = "job3.out";
StdError = "job3.err";
InputSandbox = {"JOBs/job3.sh"};
OutputSandbox = {"job3.out","job3.err"};
Requirements = other.GlueCEUniqueID=="ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam";
job3.sh
#!/bin/bash
SLEEP_TIME=${1:-0};
DO_MD5=${2:-0};
FILE_MD5=${3:-/dev/urandom};
NUM_OF_BG_JOBS=2
date
hostname
whoami
pwd
if [ "$DO_MD5" != "0" -a -r $FILE_MD5 ];then
for i in `seq 1 $NUM_OF_BG_JOBS`;do
md5sum $FILE_MD5 &
job_id=$!
jobs_array[i]=$job_id
done
fi
if [ "$SLEEP_TIME" != "0" ];then
sleep $SLEEP_TIME
fi
if [ "$DO_MD5" != "0" -a -f $FILE_MD5 ];then
for i in seq `1 $NUM_OF_BG_JOBS`;do
kill ${jobs_array[i]}
done
fi
exit 0;
JobType = "Normal";
ShallowRetryCount = 0;
RetryCount = 0;
Executable = "job2.sh";
Arguments = "0 0";
StdOutput = "job2.out";
StdError = "job2.err";
InputSandbox = {"JOBs/job2.sh"};
OutputSandbox = {"job2.out","job2.err"};
Requirements = other.GlueCEUniqueID=="ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam";
job2.sh
#!/bin/bash
SLEEP_TIME=${1:-0};
DO_MD5=${2:-0};
FILE_MD5=${3:-/dev/null};
date
hostname
whoami
pwd
if [ "$DO_MD5" != "0" -a -r $FILE_MD5 ];then
md5sum $FILE_MD5
fi
if [ "$SLEEP_TIME" != "0" ];then
sleep $SLEEP_TIME
fi
exit 0;
glite-wms-job-submit
JobType = "Normal";
ShallowRetryCount = 0;
RetryCount = 0;
Executable = "job2.sh";
Arguments = "0 0";
StdOutput = "job2.out";
StdError = "job2.err";
InputSandbox = {"JOBs/job2.sh"};
OutputSandbox = {"job2.out","job2.err"};
Requirements = other.GlueCEUniqueID=="ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam";
job2.sh
#!/bin/bash
SLEEP_TIME=${1:-0};
DO_MD5=${2:-0};
FILE_MD5=${3:-/dev/null};
date
hostname
whoami
pwd
if [ "$DO_MD5" != "0" -a -r $FILE_MD5 ];then
md5sum $FILE_MD5
fi
if [ "$SLEEP_TIME" != "0" ];then
sleep $SLEEP_TIME
fi
exit 0;
glite-wms-job-submit
JobType = "Normal";
ShallowRetryCount = 0;
RetryCount = 0;
Executable = "job2.sh";
Arguments = "0 0";
StdOutput = "job2.out";
StdError = "job2.err";
InputSandbox = {"JOBs/job2.sh"};
OutputSandbox = {"job2.out","job2.err"};
Requirements = other.GlueCEUniqueID=="ctb03.gridctb.uoa.gr:2119/blah-pbs-dteam";
job2.sh
#!/bin/bash
SLEEP_TIME=${1:-0};
DO_MD5=${2:-0};
FILE_MD5=${3:-/dev/null};
date
hostname
whoami
pwd
if [ "$DO_MD5" != "0" -a -r $FILE_MD5 ];then
md5sum $FILE_MD5
fi
if [ "$SLEEP_TIME" != "0" ];then
sleep $SLEEP_TIME
fi
exit 0;
glite-wms-job-submit
qsub qstat
qsub qdel qstat
qsub qdel qstat
pbsnodes [-o|-r|-c] node service pbs_server [stop|start]